
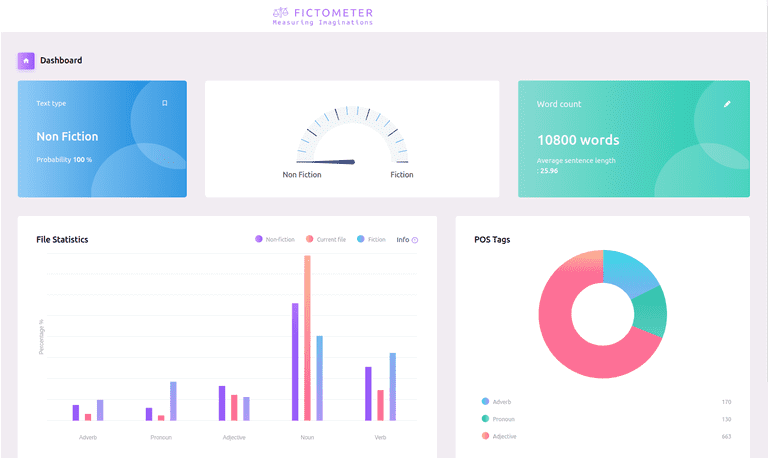
A tool to measure the imaginative writing styles in a given English text, using a Machine Learning algorithm.
This work is based on A Simple Approach to Classify Fictional and Non-Fictional Genres M. R. Qureshi, S. Ranjan, Rajakrishnan P. R. and K. Shah, StoryNLP @ ACL 2019.
In this work, we deploy a logistic regression classifier to ascertain whether a given document belongs to the fiction or non-fiction genre. For genre identification, previous work had proposed three classes of features, viz., low-level (character-level and token counts), high-level (lexical and syntactic information) and derived features (type-token ratio, average word length or average sentence length). Using the Recursive feature elimination with cross-validation (RFECV) algorithm, we perform feature selection experiments on an exhaustive set of nineteen features (belonging to all the classes mentioned above) extracted from Brown corpus text.
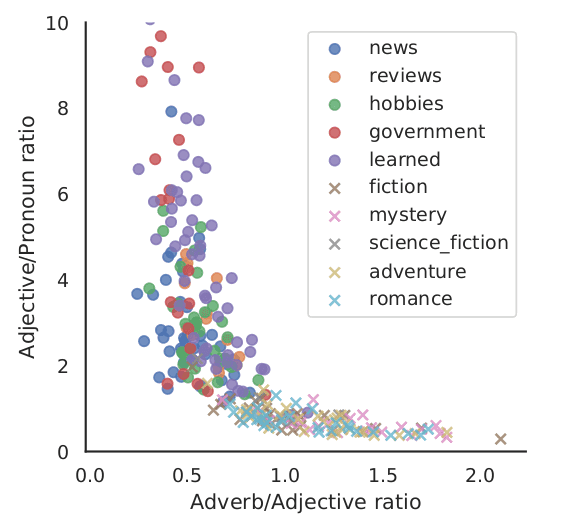
As a result, two simple features viz., the ratio of the number of adverbs to adjectives and the number of adjectives to pronouns turn out to be the most significant. Subsequently, our classification experiments aimed towards genre identification of documents from the Brown and Baby BNC corpora demonstrate that the performance of a classifier containing just the two aforementioned features is at par with that of a classifier containing the exhaustive feature set.